

[Projects]모찌케어 - 데이터 분석 및 파이프라인 구축 과정 회고
AI 기반 영유아 피부 질환 진단 서비스 ‘모찌케어’ 프로젝트 초기 단계에서 기획과 개발 타당성을 검증하기 위해 관련 데이터를 분석하려 했다. 이를 위해서 데이터 수집하고 처리하는 등 데이터 분석 파이프라인 구축 과정을 기록하려고 한다.
프로젝트 배경
‘모찌케어’는 영유아를 양육하는 부모나 양육자가 아기의 피부 사진을 찍고 증상을 입력하면 AI 기술을 활용하여 피부 질환을 진단해주는 서비스이다. 개발 전 단계에서 실제 사용자들의 니즈와 딥러닝 모델 클래스 선정 등 여러가지 정보들이 필요했기 때문에, 두 가지 방식으로 데이터를 수집했다:
- 직접 설문조사 진행 (101명)
- 네이버 카페 “맘스홀릭베이비”의 “아기 건강 질문방” 게시판에서 1년간 올라온 게시글 스크래핑 (약 65,600개)
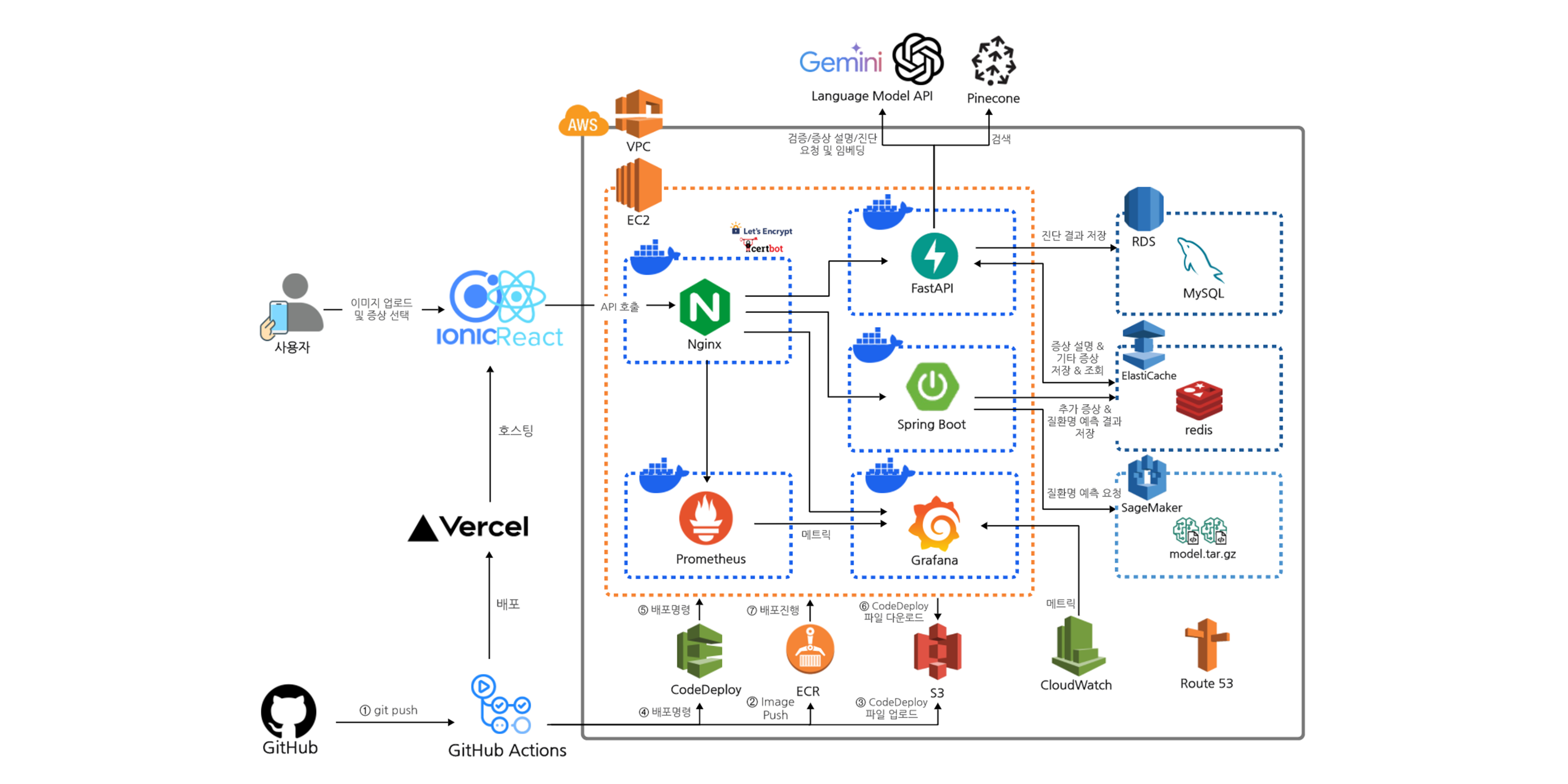
데이터 파이프라인 아키텍처 설계
수집된 데이터의 특성에 따라 처리 방식을 달리했다. ‘설문조사‘ 데이터는 규모가 작고 구조화되어 있어 로컬 환경에서 간단히 분석했지만, ‘웹 스크래핑‘으로 수집한 대량의 비정형 데이터는 AWS 클라우드 서비스를 활용한 데이터 파이프라인을 구축했다.
처음에는 파이프라인을 구축하지 않고 코드 기반으로 진행했으나, 한국어 형태소를 다루면서 분석 로직이 점점 복잡해지고 관리가 어려워졌다. 이에 따라, 데이터 마트를 구축하고 SQL을 활용한 분석 방식이 보다 효율적일 것으로 보았다.
AWS 클라우드 기반 데이터 파이프라인 구성
흐름은 다음과 같다.
- 데이터 수집 및 저장: 웹 스크래핑을 통해 수집된 원시 데이터를 AWS S3의
/raw-data버킷에 저장 - 데이터 카탈로그화: AWS Glue Crawler를 사용하여 원시 데이터를 스캔하고 데이터 카탈로그 생성
- ETL 작업: AWS Glue ETL Job을 통해 다음과 같은 정제 작업 수행
- 날짜 형식 통일
- 이모지/특수문자 제거
- 중복 공백 제거
- 제목과 내용 컬럼 통합
- 정제 데이터 저장: 정제된 데이터를 S3의
/cleansed-data버킷에 저장 - 로컬 환경 텍스트 처리:
- 형태소 분석 및 토큰 추출
- 불용어 제거
- 키워드 프레임 여부에 따른 그룹화
- TF-IDF 분석 수행
- 후속 분석용 데이터 테이블 구축
- 토큰화된 데이터 저장: 처리 결과를 다시 S3의
/tokend-data버킷에 저장 - 쿼리 및 시각화:
- AWS Athena를 활용해 SQL 쿼리로 데이터 분석
- AWS QuickSight로 결과 시각화 및 인사이트 도출
데이터 마트 스키마 설계
분석을 위해 다음과 같은 스키마로 데이터 마트를 구성했다:
이때 차원테이블(posts_dim) 같은 경우 비정규화 테이블이다. 만약 운영 중인 서버의 데이터베이스였다면, 작성자(author) 정보를 별도의 author 테이블로 분리하는 등 정규화를 했겠지만, 해당 스키마는 분석을 위한 Data Mart이므로, 조회할 때 별도 테이블 조인 없이 한번에 가져오도록 하였다.
분석 결과
로컬에서 형태소 분석과 토큰 추출 후 구축한 데이터 파이프라인과 데이터 마트를 기반으로 QuickSight를 활용해 데이터를 시각화하고, 분석한 것중 일부를 가져왔다.
1. 사용자 행동 패턴 분석
| 글 작성 빈도별 사용자 분포 (2회 이상) | 시간대별 게시글 수 |
|---|---|
| 2회 이상 글을 작성한 사용자들 중, 글을 올린 횟수별 작성자 수 분포 | 특정 기간 동안 시간대별로 게시된 글의 수 |
| 대부분의 사용자는 2~3개의 글만 남기고 떠나는 ‘단기 문제 해결형’패턴을 보인다. 커뮤니티의 소통보다는 빠르고 정확한 진단을 원하는 니즈가 존재한다고 할 수 있다. | 사용자 활동은 아이가 잠든 후인 저녁 9시~10시에 증가했습니다. ‘육퇴 후 골든타임’패턴을 보인다. |
2. 사용자 관심사와 질병, 증상 파악
| 전체 데이터 - 상위 단어 빈도수 | 전체 데이터 - TF-IDF 상위 단어 | 피부 그룹 - 상위 단어 빈도수 |
|---|---|---|
| 병원, 열, 기침같이 일반적인 단어들이 상위를 차지했다. | 감기와 같은 단어의 중요도는 낮아지고, 아토피, 두드러기, 장염같은 구체적이고 변별력 있는 질병명의 중요도가 부각됐다. | 아토피, 보습, 얼굴, 오돌토돌, 로션같은 구체적인 단어가 보인다. 사용자에게 증상을 입력받을 때 증상 체크리스트로 이용할 수 있다. |
고도화 필요
- 더 정확한 분석을 위해 해당 네이버 카페의 글을 더 스크래핑하고 분석도 자주 하려고 했기 때문에 데이터 파이프라인을 구축한 이유도 있었다. 하지만 클라우드 환경에서 한국어 처리가 쉽지 않았고(또한 Glue ETL 비용 부담도 있었다.) 결국 중간에 로컬에서 처리를 진행했다. 완전히 클라우드로 통합한다면 자동화 수준도 높일 수 있을 것이다
- MySQL의 인덱스처럼, Athena도 파티션 관련 기능(프로젝션, 인덱스, 필터링)을 적용한다면 쿼리 성능을 높이고 비용을 줄일 수 있을 것이다.
GitHub Repository: https://github.com/BabyCareAI 👈
Leave a comment