

[Projects]모찌케어 - AI 영유아 피부 질환 진단 서비스 개발 과정 회고
👶“이게 단순한 발진일까? 병원을 가야 할까?”
부모라면 고민해봤을 법한 문제를 해결하기 위해, 모찌케어 AI 영유아 피부 질환 진단 서비스를 개발했다.
이 글에선 백엔드, AI 설계 및 개발 과정에서 겪은 이슈와 결정 및 해결 과정 경험을 다룬다.
1. 서비스 개요
모찌케어 AI란?
모찌케어 AI는 아기 피부 병변 사진과 증상 정보를 종합적으로 분석하여,
✔️ 질환명 예측
✔️ 중증도 분석, 병원 내원 필요 여부 판단, 가정 내 처치 방법 안내
를 제공하는 AI 기반 서비스이다.
2. 설계 초기 단계
초기에는 최대한 빠르게 MVP 기능이 동작하여 테스트할 수 있도록 간결하게 설계하였다.
⤷ 초기에 설계한 아키텍처
사용자가 모바일 앱(Ionic React)에서 아기 피부 상태 이미지를 업로드하고 증상을 입력하면, Spring Boot 백엔드가 이를 처리한다. 업로드된 이미지는 S3에 저장되며, SageMaker의 AI 모델에 질환 예측을 요청한다. 예측된 질환명을 바탕으로 ChatGPT-4o-mini에 진단 가이드 생성을 요청하고, 최종 결과는 RDS(MySQL)에 저장된 후 사용자에게 제공된다.
Ionic 도입
모바일 앱 개발을 위한 기술을 선택하는 과정에서, 당시 프론트엔드 개발자가 없었기 때문에 다음과 같은 선택지를 두고 고민했다.
- Ionic + React 기반의 하이브리드 앱
- React Native 또는 Flutter를 활용한 크로스 플랫폼 앱
- PWA(Progressive Web App) 방식의 웹앱
React를 제외하고 전혀 사용해 본 적이 없는 기술들이었고, 선택 후 공부 시간, 그리고 선택이 잘못되었을 경우 다른 기술로 전환해서 처음부터 시작해야 하는 등의 고민점이 많았다.
다행히 이 시점에서 새롭게 합류한 프론트엔드 팀원이 React를 다룰 줄 알았기 때문에 러닝 커브를 최소화하는 방향으로 Ionic + React 조합을 최종 선택하게 되었다.
S3 도입
서비스 출시를 목표로 한만큼 사용자가 늘어나면서 저장해야 할 이미지 파일도 늘어날 것으로 예상했다. 그래서 이전에 몇 번 사용해 본 적이 있는 AWS S3를 도입하기로 결정했다. S3 도입 과정에서는 Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법 - 우아한 기술블로그👈를 참고했는데, 크게 세 가지 방법이 있다.
- Stream 업로드
- MultipartFile 업로드
- AWS Multipart 업로드
최종적으로 Stream 업로드 방식보다 오류 처리가 용이하고 동시 처리, 메모리 관리 등에서 유리한 MultipartFile 업로드 방식을 선택했다. 구현과 업로드 과정이 복잡하고, S3 의존성이 높은 AWS Multipart 업로드 방식은 배제했다. (해당 블로그에서는 최대 20MB 프로필 이미지 업로드 기능을 개발할 때 AWS Multipart 업로드 방식을 사용하면 오버 엔지니어링이라고 언급하고 있다.)
⤷ 우아한 기술블로그 참고
이때 추가 고려 사항이 있었다
- AI 개발자는 원본 비율이 아닌 고정 크기 리사이징 처리로 모델을 검증 및 테스트하였다. 따라서 배포된 모델을 통해 추론 시 입력되는 이미지 또한 고정 크기로 리사이징 처리된다.
- 그러나 사용자 입장에서는 이전에 자신이 업로드한 사진을 조회할 때는 원본 비율로 보여야 한다.
이런 이유로 두 종류의 리사이징된 이미지를 저장하는 것도 고려하였으나, 스토리지 비용을 고려하여 원본 이미지를 저장하고 용도에 맞게 리사이징하는 방법을 선택하였다.
또한 업로드 되는 원본 이미지가 클 경우를 대비해서 프론트엔드에서 사용자 지정 이미지 커팅 기능(정사각형)과 가로 세로 384px로 리사이징 되어 서버로 전달되도록 하기로 했다.
AWS SageMaker의 주요 패턴
SageMaker는 다양한 추론 방식(Serving Pattern)을 지원한다.
- 실시간 추론(Real-time Inference)
- 배치 추론(Batch Inference)
- 비동기 추론(Asynchronous Inference)
- 서버리스 추론(Serverless Inference)
- 등등
이 중에서 비동기 추론과 서버리스 추론 중 어떤 방식을 사용할지 고민했다.
비동기 추론은
이미지 전처리 및 예외 처리를 거친 결과, 페이로드(모델이 입력으로 받는 데이터)가 4MB 이하로 유지될 것으로 예상되었고,
서버리스 추론의 콜드 스타트(Cold Start) 문제는 프로비저닝된 동시성Provisioned Concurrency👈 옵션을 활용하면 해결할 수 있다고 판단했다.
이에 따라 비용 절감 효과가 가장 큰 서버리스 추론을 최종적으로 선택했다.
(무엇보다 비동기 추론은 비용 부담이 컷다.)
패턴 선택에 있어서는 해당 링크👈를 참고했다.
Langchain4j 도입
SageMaker를 통해 딥러닝 모델을 배포한 후, 해당 모델이 생성한 진단 결과에 대한 답변의 질을 향상시키기 위해 Spring Boot 프레임워크 내에서 Langchain4j 라이브러리를 활용하여 OpenAI API를 호출하고 의료 가이드를 자동으로 생성하는 시스템을 구축하였다.
한계점
Spring Boot와 Langchain4j를 활용해 OpenAI API를 통한 단순한 진단 및 가이드 응답 제공에 성공했다. 이후, 팀에서는 진단 프로세스를 더욱 발전시키기 위해 다양한 방안을 지속적으로 논의했다. 이 과정에서 RAG와 Agent 같은 기술도 논의되었으나, 자바 언어만으로 개발하는 데에는 한계가 있음을 느꼈다.
예를 들어) 기존에는 Langchain 강의를 들으며, 프로젝트에 필요한 파이썬 코드를 Langchain4j 문서를 참고하여 자바로 변환하며 불편하게 개발하고 있었다. 그런데 Langchain4j 문서에서 갑자기 파이썬의 체인(Chain) 기술을 배제하고, 자바에 맞춘 AI 서비스 (AI Service)라는 새로운 개념을 도입하니, 이를 학습하고 적용하는 데 시간도 들고 무엇보다 점점 복잡해지는 것을 느꼈다.
이때쯤 아쉽게도 참가하던 대회 본선에서 탈락을 하는 바람에, 팀원들과 다음을 기약하고 1인 개발을 하기 시작하였다.
3. 고도화
⤷ 고도화한 아키텍처 다이어그램
FastAPI 도입
이를 해결하기 위해 LLM 처리 전용 서버를 FastAPI 기반으로 구축하여 해당 기능을 전담하도록 하고, 나머지 기능은 Spring Boot가 담당하는 구조로 변경하였다.
파이썬 서버 하나만으로 나머지 기능을 담당하는 것도 가능하다 봤지만, Spring Boot를 주로 공부해왔기에 기존 코드를 재활용하는 편이 개발 속도에 있어서 더 효율적이라고 판단했다.
Nginx도입
추가적으로 Spring Boot와 FastAPI를 동시에 운영하기 때문에 IP/포트가 외부에 노출하지 않고 단일 도메인으로 API 요청을 라우팅하게끔 Nginx를 도입하여 리버스 프록시 용도로만 사용하였다. 또한 인증서를 발급하여 HTTPS(SSL/TLS) 트래픽을 처리하도록 하였다.
redis 도입
단순히 두 서버(SpringBoot, FastAPI)의 데이터 통신용으로 MySQL(RDBMS)을 사용하기 보다 redis(In-memory 저장소)를 사용하여 캐싱하는 방식으로 변경했다. 이미지는 S3에 저장이 되며 나머지 과정에서 입력 및 산출되는 데이터들은 “최종 진단” 단계에서 모이므로 가장 마지막에 한꺼번에 DB에 저장하는게 좋다고 생각했다.
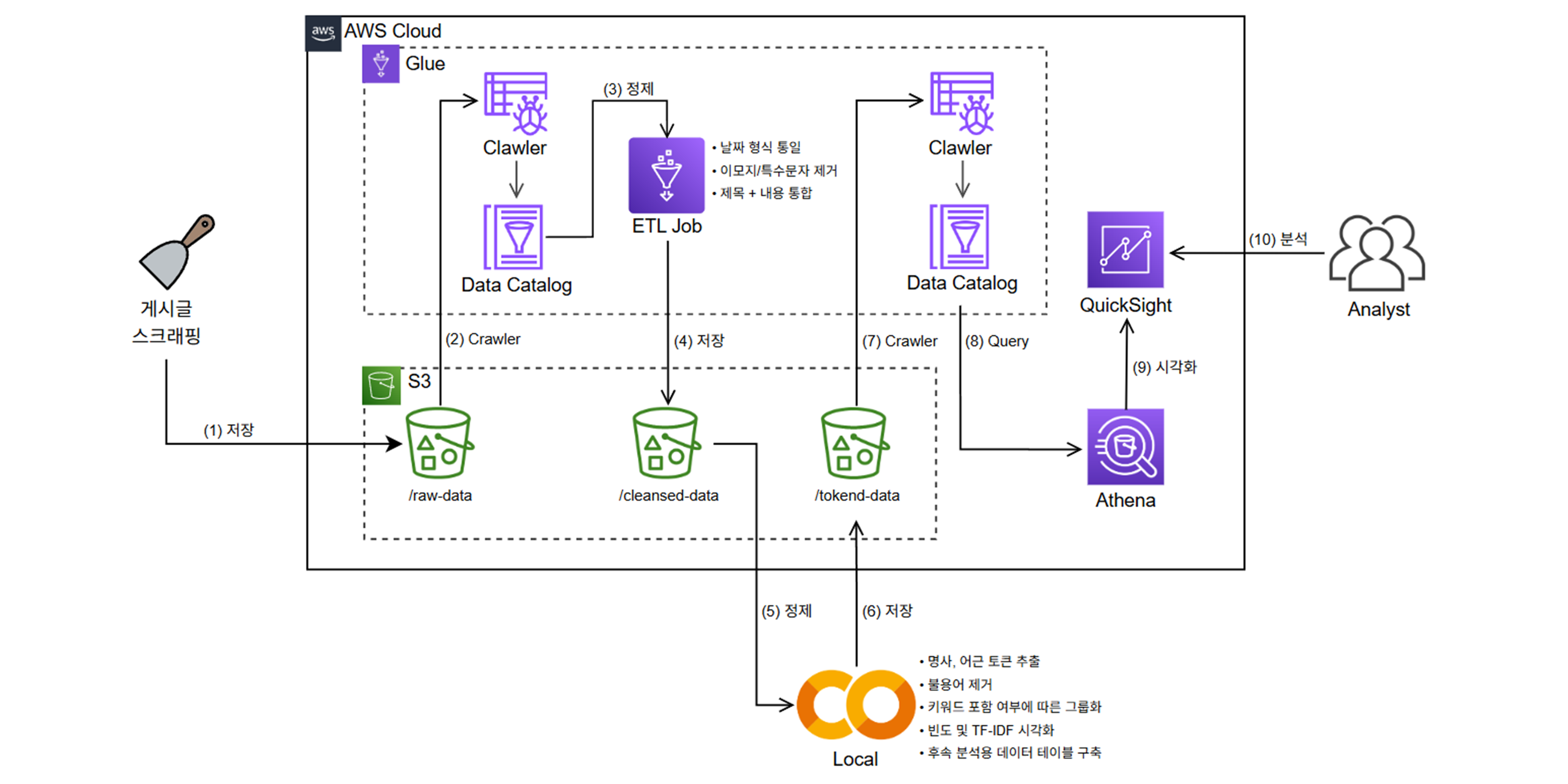
진단 프로세스
백엔드 기준 진단의 과정은 다음과 같다.
⤷ 진단 프로세스
프롬프트 엔지니어링에 여러 단계의 프롬프트를 유기적으로 연결하는 기법인 “프롬프트 체이닝”이라는 기법을 착안하여 진단 프로세스를 설계하였다. 단순하게 설명하면 사용자(이미지, 선택 증상, 기타 증상)데이터와 의료 지식 베이스를 참조하여 진단을 내리도록 하는 프로세스이다. 다만 의료 지식 베이스를 더 잘 참조(검색)하고 더 정확한 진단을 내리도록 과정을 세분화하였다. 이때 “프롬프트 체이닝”은 각 단계마다 발생할 수 있는 오류가 후속 단계로 전파되어 전체 결과의 신뢰도를 저하시킬 수 있으며 긴 체인에서 초기의 중요한 맥락 정보가 점차 희석되거나 손실될 수 있는 위험성이 있는데 본 프로젝트에는 중간 중간 검증을 거치고, 오류가 의심되면 진단에 악영향을 주지 않기 위해 과감하게 버리며, 캐시를 활용하여 컨택스트 손실을 해결하려고 했다.
참고 링크: 프롬프트 체이닝의 모든 것 (카카오 클라우드)👈
사용자 기준에서 이미지 업로드API와 추가 증상(기타 증상) 입력을 제외한 나머지 과정들은 자동적으로 실행되어야 한다. 이 과정에서 메시지 큐(Kafka, RabbitMQ 등)를 통해 API 호출을 큐에 넣고 서버가 하나씩 처리할 수도 있지만, 기존 방법(클라이언트 측에서 호출)대로 진행하는 것이 복잡하지 않고 개발 시간을 늘리지 않을 것 같았다
RAG 파이프라인 (최종 진단 API)
⤷ RAG 파이프라인
위에 진단 프로세스에서 적혀있듯이 최종 진단은 RAG 기법을 활용하여 내리도록 하였다.
의료 지식 베이스스는 영국 베이비센터 👈 여기의 문서를 기반으로 전처리 및 질병명, 증상, 증상 부위 등으로 메타데이터를 구성하였다. 이후 해당 json파일을 청크별로 나누어 임베딩 한 후, Pinecone 벡터DB 서비스에 저장하였다.
⤷ 질병 지식 베이스의 임베딩 결과를 UMAP 알고리즘 사용하여 차원 축소하여 시각화 한 이미지
- 서로 가깝게 위치하는 질병들은 증상이 유사하거나 연관성이 높은 질병들임을 알 수 있다. 이 질병들은 판별 기준이나 차이점을 제시해야 정확한 진단이 이루어 질 수 있을 것이다. (예를 들어 ”Athlete’s foot”과 “Ringworm”은 둘 다 곰팡이 감염으로 인한 피부 질환이며, 증상도 비슷하다. 하지만 발생 부위가 다르기 때문에 쿼리에 이런 차이점을 입력되도록 해야 할 것이다.)
- 멀리 떨어져 있는 질병은 특징적인 증상이나 발병 부위가 명확하여 다른 질환들과 혼동되지 않을 것이다. (예를 들어 “HFMD”는 발진이 주로 손, 발, 입에 나타나기에 전신 및 특정 다른 부위에 나타나는 다른 질병들과 혼동이 되지 않을 것이다.)
API 구성은 진단 ID를 매개변수로 요청이 오면 redis에서 캐싱 된 모든 데이터를 취합하여 임베딩 후 벡터DB에서 유사도 검색을 통해 관련된 문서 Top 4를 받아온다. 그렇게 얻은 문서와 함께 프롬프트로 최종적으로 LLM에게 진단을 요청한다. 이때 프로프트에 CoT(Chain-of-Thought)를 적용하여 추론 과정을 단계별로 설명하도록 유도해서 논리적 사고를 통해 최종 진단을 생성하도록 했다.
CoT 참고링크: 프롬프트 엔지니어링이란 - 고급 기법 (CoT) - 카카오클라우드👈
진단 정확도 테스트
모찌케어 서비스가 잘 개발되었는지 알기 위해서는 테스트를 해야 하고 그중에서 진단 정확도 테스트가 중요하다고 판단했다. 하지만 진단 결과에 영향을 끼치는 모든 요소들을 다 다르게 설정하여 테스트하기엔 그 수가 많다고 판단하였다. 그래서 우선 임의로 조건을 설정하고 고정해서 테스트와 진단 정확도 개선 작업을 반복하였다.
모찌케어의 진단 정확도 테스트 조건
- 영상 기반 질환 분류 모델을 학습할 때 사용한 테스트셋(4개의 질환), 총 143개의 이미지를 사용했다.(진단에는 총 34개의 질환에 가능성을 열어두지만 방금 언급한 4개의 질환 외의 나머지 질환들을 테스트할 마땅한 사진 데이터를 찾기가 어려웠다.)
- “기타 증상 API” 경우에도 사용자가 입력하지 않았다는 가정하에 진행했다.
- 사용자가 추가 증상 0개~4개를 입력한 경우를 나누었고, 각 입력 증상이 외부데이터(RAG) 증상(메타데이터)에 포함되는 개수를 기준으로 경우를 나눴다.
진단 정확도 개선
방법1 - 메타데이터 증상 정보 세분화 및 부위 정보 추가
처음에는 사용자가 선택하는 증상의 종류를 10개 정도로 정의했지만 사용자가 증상을 선택하는 시간(몇초에서 최대 몇분)을 줄이는 장점보다 진단 정확도를 높이는것이 더 중요하다고 보았고, 의료 지식 베이스(json)의 메타데이터에 증상 정보를 세분화하고, 사용자가 더 많은 증상을 선택하여 입력받도록 했다.
또한 메타데이터에 부위 정보를 포함시키고, 마찬가지로 사용자가 업로드한 이미지에 부위를 선택하여 입력받도록 하였다.
방법2 - Top K 및 모델 변경
테스트 결과:
기존에는 Top k를 10으로 설정했었다.(Long Context Reordering 적용) 이후 2씩 줄여가며 여러 번 테스트를 반복하였고, Top K를 4로 설정하니 진단 정확도가 가장 높게 나왔다. 많은 검색 결과를 context에 포함하기 보다 관련성 높은 검색 결과만에만 집중하도록 하는게 진단 정확도가 높아졌음을 알 수 있었다.
또한 최종 진단 모델을 gemini-2.0-flash-lite에서 gpt-4.1-mini로 변경하였고 진단 정확도가 높아졌음을 알 수 있었다.
방법3 - 질환 분류(CV model) 결과 쿼리에 추가
RAG만을 통한 진단은 부위,증상,이미지설명을 쿼리로 의료 지식 베이스와의 유사도를 통한 진단이기 때문에 증상 부위가 뚜련한 “HFMD”같은 경우 잘 검색한다. (위 임베딩 시각화 이미지를 보면 “HFMD”는 다른 질환과 떨어져 있다.)
하지만 사용자가 입력한 부위,증상이 반드시 의료 지식 베이스에 해당하는 부위와 포함되지 않는 경우도 반드시 있기 때문에 진단 정확도가 낮을 수 있다.
그리고 아래 이미지처럼 “shingles”이미지를 테스트 했을 때 모두 검색 결과에는 포함되어있지만 적었고, 최종 진단 결과에는 전부 포함되지 않았다. 결과를 열어서 확인해보니 “shingles”이 검색 결과에는 포함되어있는 이미지의 최종 진단 결과는 대부분 chickenpox이었다. “chickenpox”와 “shingles”는 코사인 유사도가 매우 가깝기도 하고, “shingles”는 영유아에게 매우 드물게 발생하기 때문에 Cot과정에서 배제되어 chickenpox가 도출 된 것이다.
그래서 AI 개발자님께서 학습시킨 질환 분류(vision)모델의 추론 결과(임계치를 넘긴 결과 한정)를 쿼리에 추가하여 검색과 Cot과정에서 힌트를 주도록 했고, 진단 정확도가 높아졌음을 알 수 있었다.
⤷ 질병 진단 정확도 비교
- 수두(Chickenpox): 21.74% ~ 47.83%에서 60.87% ~ 82.61%로 상승
- 수족구병(HFMD): 67.39% ~ 78.26%에서 89.13% ~ 100%로 상승
- 습진(Eczema): 31.91% ~ 46.81%에서 89.36% ~ 91.49%로 상승
- 대상포진(Shingles): 0%에서 61.54% ~ 76.92%로 상승
위 방법들을 통해서, 테스트 데이터셋 기준, 전체 평균 진단 정확도를 44.0%에서 95.6%로 51.6%p 향상하였다.
쉽게 예를 들면, 수족구의 여러 증상 중 ‘열’과 같은 증상 하나만 입력하고 수족구 사진을 업로드하면, 모찌케어는 90% 정확도로 수족구라고 맞춘다.
⚠️ 이 테스트 결과는 영상 기반 질환 분류 모델을 학습할 때 사용한 테스트셋 (4개의 질환)만으로 테스트했기 때문에 다른 질병의 진단 정확도는 확인 되지 않았으며, 영상 기반 질환 분류 모델의 추론 결과(threshold:50)가 쿼리에 포함되어 검색되고, 해당 모델의 성능에 영향을 받기 때문에 다른 질병의 진단 정확도는 이보다 낮을 수 있다.
진단 결과 저장
현재 많은 기능을 개발한 것처럼 보일 수 있지만, 전체적으로는 ‘진단’이라는 MVP만을 구현한 상태이며, 그 결과는 하나의 단일 테이블에 저장되도록 했다. 이런 구조만 놓고 보면 NoSQL도 고려해볼 수 있지만, 이후 회원 가입, 커뮤니티 등 기능이 확장되면서 여러 테이블이 필요해질 수 있기 때문에, RDBMS를 사용하는 것이 더 적합하다고 판단했다.
⤷ diagnosis_results 테이블
처음에는 diagnosis_result 테이블의 PK를 diagnosis_id(uuid)로 설정하며 최종진단이 끝나면 upsert를 통해 기존의 diagnosis_id해당하는 컬럼이 있으면 update하고, 없으면 insert하는 식으로 하였다.
하지만 uuid는 문자열이며, 길고, 정렬이 어려워, upsert를 매번 하는것보다, 굳이 조회하지 않고, insert만 하도록 하는게 좋아보였다. 그래서 autoincrement id를 PK로 새롭게 적용하고(자동 인덱스 설정), diagnosis_id는 유니크 제약조건을 빼고 일반 컬럼으로 두었다.
4. 두번째 고도화
⤷ 두번째 고도화된 아키텍처 다이어그램
모니터링 도입
Grafana를 통해 대시보드를 구축했다. EC2, RDS, ElastiCache 등 AWS 자원의 기본 지표와 CloudWatch Agent를 통해 EC2의 메모리/디스크 사용률을 수집하고 Prometheus로 API 요청 수와 처리 시간을 시각화하였다.
⤷ Grafana
또한 기능에 따라 여러 LLM API를 사용하기 때문에 LangSmith를 통해서 LLM 호출을 추적하고, 성능과 비용 등을 모니터링 하였다.
⤷ LangSmith
배포 자동화 도입
⤷ 배포자동화 전략
초기에는 서버를 한개만 사용하고 있기 때문에 Github Actions에서 직접 EC2 인스턴스에 SSH로 접속하여 배포하는 방식으로 진행했지만, Github Actions 스크립트가 점점 복잡해짐을 느꼈고, 위 다이어그램과 같이 AWS ECR, CodeDeploy, S3를 도입하여, 배포 스크립트를 역할 별로 분리하여 관리하였다. 이를 통해 어디에서 문제가 생겼는지 파악하고, 이력을 추적하기 쉬워졌다. (추후 무중단 배포를 적용할 예정이다.)
성능 테스트 결과
⤷ Artillery report.html
마지막으로 Artillery 툴을 사용하여 최종 진단 API를 성능테스트해보았다. 이때 검색 쿼리로 사용될 redis에 데이터가 모두 다르게 구성된 diagnosis_id 리스트를 입력으로 하여 테스트하였다. arrivalRate(초당 요청수)를 0.05에서 0.75까지 여러 페이즈로 구성하였고 그 결과, Latency는 최소 1224ms (약 1.2초), 최대 8576ms (약 8.6초), p95 5653.6ms (약 5.7초)를 기록한 것을 확인할 수 있었다. 또한 0.6~0.75 RPS 단계부터 스트레스를 받기 시작하여 500에러가 나오기 시작하였고, 일부 요청에 대한 응답 시간이 확연히 늘어나는 것을 알 수 있었다.
5. 모찌케어 중간 시연 영상
중간에 팀 프로젝트에서 개인 프로젝트가 되면서 기존 다른 팀원이 담당하던 프론트엔드(Ionic + React 기반 하이브리드 앱)개발을 이어가기 어려웠고, 일단은 부족하게나마 Streamlit으로 웹앱을 구현하고 녹화하였다.
6. 현재
앞서 진행한 진단 정확도 테스트와 성능 테스트의 결과처럼 아직 앞길이 멀다.(LangGraph, AWS Bedrock Agents를 활용한 워크플로우 고도화, 프롬프트 개선, 최적화 등 적용해볼만한게 자꾸만 생긴다.)
한편으로 시중의 괜찮은 서비스 하나 완성하기까지 얼마나 많은 노력과 연구가 필요한지 새삼 깨닫게 된다.
GitHub Repository: https://github.com/BabyCareAI 👈
Leave a comment